1. Introduction

Earlier
this month the National Academy of Technologies of France (NATF) issued its report on the
renewal of artificial intelligence and machine learning. This report is the
work of the ICT (Information and Communication Technology) commission and may
be seen as the follow-up of its
previous report on Big Data. The
relatively short 100 pages document that was released builds on previous
reports such as France
IA report or the White
House reports. It is the result of approximately 20 in-depth interviews (2
hours) with various experts from academy, software providers, startups and
industry.
AI is a
transforming technology that will find its way
into most human activities. When writing this report, we tried to avoid
what had been previously well covered in the earlier reports – which are
summarized on pages 40-45 – and to focus on three questions:
- What is Artificial Intelligence today?, from a practical perspective – from an AI user perspective. Although the “renewal” of interest in AI is clearly the consequence of the extraordinary progress of deep learning, there is more to AI than neural nets. There is also more to AI than the combination of symbolic and connectionism.
- What recommendations could be made to companies who are urged everyday by news article to jump onto the “AI opportunity” – very often with too much hype about what is feasible today ? Many startups that we interviewed feared that the amount of hype would create disillusion (“we bring a breakthrough, but they expect magic”).
- What could be proposed to public stakeholders to promote the French Artificial Intelligence Ecosystem, in the spirit of Emmanuel Macron’s discourse. Because of the diverse background of the NATF members, and because of our focus on technology, software and industrial applications, we have a large perspective of the AI ecosystem.
We never
start to write a report without asking ourselves why yet another report would
be needed. In the field of AI, Machine Learning or Big Data, more reports have been written than a bookcase would hold. Our “innovation thesis” – what
distinguishes our voice from others – can be roughly sumarized as follows:
- The relative lag that we seen in France compared to other countries such as the USA when looking at AI applications is a demand problem, not a supply problem. France has enough scientists, startups and available software to surf the wave of AI and machine learning and leverage the powerful opportunities that have arisen from the spectacular progress in science, technology and practice since 2010.
- Most successful applications of Artificial Intelligence and Machine Learning are designed as continuous learning and adaptive processes. Most often, success emerges from the continuous improvement that is fed by the iterative collection of feedback data. The “waterfall” cascade “business question -> specification of smart algorithm -> implementation -> execution” is something of the past century.
- There is no successful AI application without software mastery. This is actually a consequence of the previous point as this blog post will make abundantly clear.
- Similarly, AI success is most often drawn from future data more than past data. Too much emphasis has been put on “existing data as gold” while existing data in most company is often too sparse, to heterogenous, without the relevant meta-data (annotations). Data collection is a continuous active process, not something that is not once, to ensure that insights derived from AI are both relevant to the current world and constantly challenged by feedback.
This blog
post is both intended as a short summary for English-speaking readers and a
teaser for those who should read the full report. It is organized as follows.
Part 2 describes the “tool box” of available AI techniques and attempts to give
a sense of which are better suited to which types of problems. This part
represents a large share of the full report, since we found after a few
interviews that it was truly necessary to show what AI is from a practical
viewpoint. Most existing successful industrial applications of AI today are not
deep neural nets … while at the same time getting ready to leverage this “new”
technology through massive data collection is urgently necessary. Part 3
details a few recommendations for companies who want to embark into their “AI
journey”. From collecting the right amount of data, securing a large amount of
computing power, ensuring a modern and open software environment to running
teams in a “data science lab” mode, these recommendations are focused of favoring
the “emergence” of AI success, rather than a top-down, failure-proof approach. The
last part takes a larger perspective at the AI ecosystem and makes some
suggestion about improving the health of our French AI applications. This last
part is a follow-up to a number of brilliant posts about the “Villani report on AI” and the lack
of systemic vision, such as Olivier Ezratty
detailed and excellent review, Philippe
Silberzhan criticism on the French obsession with “plans” and Nicolas
Collin superb article about innovation ecosystems.
2. Taking a wide look at AI and ML
The
following picture is borrowed from the report (page 52) and tries to separate
five categories of AI & ML
techniques, sorted along two axes which represent two questions about the
problem at hand:
- Is the question narrowly and precisely defined – such as recognition of a pattern in a situation - or is it more open-ended ?
- Do we have lots of data available to illustrate the question – and to train the machine learning algorithm – or not ?
Sorting the
different kinds of AI techniques along these two axes is an obvious
simplification, but it helps to start. It also acts as a reminder that there is
more than one kind of AI ... and that the benefits of Moore’s Law apply
everywhere.

Let us walk
quickly through each five categories:
- The “agent / simulation” category contains methods that exploits the available massive computational power to run simulation of smart agents to explore complex problems. Sophisticated interaction issues may be explored through the framework of evolutionary game theory (for instance, GTES : Game-Theoretical Evolutionary Simulation). There exists a very large variety of approaches, which are well suited to the exploration of open questions and complex systems. COSMOTECH is a great illustration of this approach.
- The “semantic category” is well illustrated by IBM Watson, although Watson is a hybrid AI system that leverages many techniques. The use of semantic networks, ontologies and knowledge management techniques has allowed “robot writers” to become slowly by surely better at their crafts, as illustrated by their use in few news articles. These techniques are well suited to explore very large amount of data with an open-ended question, such as “please, make me a summary”.
- The middle category, which applicability spans over a large score, is made of “classical” machine learning and data mining algorithms, which are used today in most industrial applications (from predictive maintenance to fraud detection). This category is in itself a “toolbox” with many techniques that ranges from unsupervised clustering (very useful for exploration) to specific pattern recognition. Getting the best of this toolbox may be obtained through a “meta AI” that helps to select and parameterize the best algorithm or combination thereof. Einstein from Salesforce or TellMePlus are great illustration of these advanced “meta” AI techniques.
- The fourth category is a combination of GOFAI (Good Old-Fashion AI), Rule-Based Systems, Constraint and generic problem solvers, theorem provers and techniques from Operations Research and Natural Language Processing. Here also, the toolbox is very large; putting these techniques into an AI landscape usually irritate scientists from neighboring domains, but the truth is that the frontiers are very porous. The interest of these approach is that they do not require a lots of training data, as long as the question is well defined. Although “expert system” sounds obsolete, many configuration and industrial monitoring systems are based on rules and symbolic logic.
- The fifth category is deep learning, that is the use of neural nets with many layers to solve recognition problems. Deep neural nets are extremely good at complex pattern recognition problems such as speech recognition or machine vision. On the other had they require massive amount of qualified data to train. DNN are the de facto standard method today for perception problems, but their applicability is much larger (portfolio management, geology analysis, predictive maintenance, …) when the question is clear, and the data is available.
This is a somewhat
naïve classification but is allows for a complete “bird view”. A more
up-to-date, such as PWC list of Top
10 AI technology Trends for 2018, is necessary to better understand where
the focus is today, but is usually more narrow and misses the contribution of
other fields. A short description of deep neural nets (DNN) and convolution
neural nets (CNN)
is proposed in our report, but this is a fast moving field and recent online
articles such as “Understanding
Capsule networks” have an edge on written reports. There are still many
open issues, that are recalled in the report, such as explicability
(mostly for deep learning – which is one of the reason the other techniques are
often preferred), the robustness of the trained algorithm outside its training
set, the lack of “common sense” (a strength of human intelligence versus the
machine) and the ability to learn from small data sets.
Even if
deep neural nets may not deserve to be called a “revolution” considering that
they have been around for a while, the spectacular progress seen since 2010 is
a definitely a game changer. From AlphaGo and machine vision to automatic speech
recognition, the reports recalls a few of the dramatic improvement that the
combination of massive computing power, very large annotated data sets and
algorithmic improvements have produced. This is “almost a revolution” for two
reasons. First, although they require massive amount of training data and a
precise question to work on (of the classification kind), DNN are very broad in
their applicability. With the large availability of libraries such as
TensorFlow, DNN has become a new, general purpose, tool in the tool box that
may be applied to all types of applied business problems. Second, in a “system
of systems” approach, DNN provide “perception” to smart systems, from machine
vision to speech recognition, that may be used as input for other techniques.
This is obviously useful when explainability is required. In a biomimetic way,
DNN provides the low-level cognition methods (the recognition of low level
patterns) while more classical methods ranging from rules to decision trees
propose an explainable diagnosis. Similarly, semantic techniques and DNN for
speech recognition work well together. It is clear that the “revolution” caused
by the progress of DNN is in front of us, especially because machine vision
will become ubiquitous with the combination of cheap cameras and neuromorphic
chipsets.
The beauty
of AI, and what makes it hard to understand from the outside, is the richness and
complexity of techniques that allow the customization and combination of the
techniques presented in the previous picture. There is an emerging consensus
that the next generation of AI breakthroughs will come from the combination of
various techniques. This is already the case today : many of the extraordinary
systems, such as Watson,
AlphaGo or Todai
Robot, use a number of techniques and meta (hybridization) techniques. Here
is a short overview to appreciate the richness of possible hybridization :
- Reinforcement Learning has been around for a long time, it is one of the oldest technique from AI that is based on a continuous loop of incremental changes directed through a reward function. Libratus, the extraordinary AI poker player is based on the combination of smart reinforcement learning and non-connectionist machine learning.
- Randomization (such as Monte-Carlo approach) and massive agents communities are borrowed from simulation methods to help explore large search space. They are often combined with “generation” methods, that are used to randomly explore parameterized sets of models, to produce additional data sets when not enough data is available, to explore meta-heuristic parameter sets (the smart “AI factories” such as Einstein or TellMePlus are examples of such approaches) or to increase the robustness such as the “Generative Adversarial Networks” example.
- Evolutionary Game Theory brings game theoretical equilibriums such as Nash equilibrium into the iterative reinforcement loop (searching for the fixed point of what game theorists call the “best response”). Evolutionary game theory is great for simulating a smart group of actors that interact with each other (versus a unique single “smart” system).
- Modular learning is based on the idea that some low-level behavior may be learned on one data set and transferred to another learning system. In the world of neural nets, we speak of “transfer learning”. Modular learning is related of “systems of systems” architecture which is in itself a complex topic that will deserve a complete blog post. I refer as an example to the event-driven architecture proposed in this older post, which also related to biomimicry ( using not only the cortex, but the full cognitive/perception/emotion human system as an inspiration).
What is not covered in the report due to lack
of time, is the “meta-meta level”, which is how the previous list of
meta-techniques can be combined, as they often are in truly advanced systems.
This shows that the first figure is naïve by construction and that practice
really matters. Knowing the list of primitive techniques and algorithms is not
enough to design a “smart” system that delivers value in a robust manner. There
is no surprise there, most of these meta/combination methods have been around
for a long time and used, for instance, in operations research application
development.
3. Growing Continuous Learning Data Processing Flows

The first and main message that the report conveys to aspiring AI
companies is to build their “training data set” strategy. There is nothing
original here, this is the advice that comes from all kinds of experts (see the
report), but there is more to it than it may sound.
- The foundation of an AI strategy, as well as a digital strategy, is to collect, understand and distribute the data that is available to a company. Collecting data into data lakes require a common shared business data model (data models are the corner stone of digital transformation, as well as collaborative and smart systems); collating data into training data sets require meta-data that captures business know-how as much as possible. I refer the reader to the “Mathematical Corporation” book that is full of great examples of companies that have started their AI journey with a data collection strategy.
- Although it is not necessary to start experiment with deep learning at first (simpler methods often deliver great results and make for an easier first step in the learning curve), each company should become ready to leverage the transforming power of deep neural nets, especially in the machine vision field. As a consequence, one must get ready for collective massive data sets (millions to billions sample) and start to collect images and video in an industrial manner.
- One must think about AI applications as processes that are built from data, meta-data, algorithms, meta-heuristics and training protocols in a continuous iterative improvement cycle. For most applications, data needs to be collected continuously, both to get fresh data that reflects the present environment (versus the pas) and to gather feedback data to evaluate the relevance of the training protocol. Autonomous robots are perfect examples of this continuous data flow acquisition and processing cycle.
- The most critical expertise that companies will develop through time are the annotated data and the training protocols. This is where most of the business knowledge and expertise – hence the differentiation - will crystallize. Algorithms will often be derived semi-automatically from the training sets (cf. the “data is the new code” motto from our previous report).
The second message of the report is that the time to act is now. As
shown from the examples presented in “The Mathematical Corporation” or those
found in our report, the “AI toolbox” of today is already effective to solve a
very large number of business problems and to create new opportunities.
- As stated in the introduction, Artificial Intelligence is a transforming technology. The journey of collecting, analyzing, and acting on massive amounts of business data tend to transform business processes and to produce new business insights and competitive IP.
- AI is a practice, it takes time to grow. The good news is that AI expertise about your business domain is a differentiating advantage, the bad news is that it takes time and it is hard to catch up with your competitors if you get behind (because of the systemic effect of the loop that will be shown in the next section).
- Computing power plays a critical role with the speed at which you may learn from data. In the past two years, we have collected a large evidence set of companies that have accelerated their learning by orders of magnitude when switching from regular servers to massive specialized resources such as GPU or TPU (ASIC).
- Everything that is needed is already there. Most algorithms are easily available in open-source libraries. Many AI “workbench” solutions are available that facilitate the automatic selection of learning algorithms (to Einstein and TellMePlus we could add Holmes or Solidware, for instance).
The
following picture – taken
from a presentation at MEDEF last year -
illustrates the conditions that need to be developed to be “AI-ready”.
In many companies, the right question is “what
should we stop doing to prevent our teams from developing AI ?” versus “ what should we do/add/buy to develop our AI
strategy ?”. This picture acts as “Maslow pyramid” : the foundation is the
understanding that creating value from these approaches is an emergent process,
that requires to “hedge one’s bets” and rely on empowered, distributed and
autonomous teams.
The second step is, as we just saw, to collect data and to grant access widely,
modulo the privacy and IP constraints. The third step is to give the teams
access with the relevant software environment: as up-to-date as possible,
because algorithmic innovation is coming from the outside in a continuous flow,
and with enough computing power to learn fast. Last these teams need to operate
with a “data lab culture”, which is a combination of freedom and curiosity
(because opportunities may be hidden from first sight) together with scientific
rigor and skepticism. False positives, spurious correlation, non-robust
classifiers … abound in the world of machine learning, especially when not
enough data is available.

The third message that the reports addresses to companies is to think of
AI in terms of flows (of enriched data) and (business) processes, not of technologies
or value-added functions.
- Although this is not a universal pattern, most advanced AI systems (from Amazon’s or Netflix’s recommendation engines to Criteo or Google AddSense add placement engines, through Facebook or Twitter content algorithms) are built through the continuous processing of huge flows of data as well as the continuous improvements of algorithms with millions of parameters. Distributed System Engineering and Large Data Flows Engineering are two critical skill domains to successfully bring AI to your company.
- One must walk before running: there is a learning curve that applies to many dimensions. For instance, the path to complex algorithms must be taken step by step. First one play with simple libraries, then you associate with a local expert (university faculty member, for instance). Then you graduate to more complex solutions and you organize a Kaggle or local hackathon to look for fresh ideas. Once you have mastered these steps, you are in a better position to hire a senior expert at the international level, provided that your problem is worth it.
- “Universal AI” is not ready : AI for your specific domain is something that needs to be grown, not something that can be bought in a “ready for use” state. Which is why most of the experts that we interviewed were skeptics about the feasibility of “AI as a service” yet (with the exception of lower-level components such specific pattern recognition). Today’s (weak) AI is diversified to achieve the best results. The great “Machine Learning for Quantified Self” book is a good illustration: none of the techniques presented in this book are unique to Quantified Self, but the domain specificity (short time series) means that some classical techniques are better suited than others.

- The numerous examples from the report or “The Mathematical Corporation” show that data collection must expand beyond the borders of the company, hence one must think as a “data exchange platform”. This is another reason why software culture matters in AI : open data systems have their own ecosystems, mindsets and software culture.
4. How to Stimulate a Demand-Based Application Ecosystem
The following figure is taken from the press conference when we
announced the report. It illustrates the concept of “multiple AI ecosystems”
around the iterative process that we have just mentioned. The process is the
backbone of the picture: pick an algorithm,
apply it to a data set to develop a “smart” system, deliver value/services from
running this new system, develop its usage and collect the resulting data that
will enrich the current data set (either to continuously enrich the dataset or
to validate/calibrate/improve the precision/value of the current system), hence
the loop qualified as “Iterative development of AI practice”. Each of the five
steps comes with its own challenges, some of which are indicated on the figure
with an attached bubble. Each step may be seen as an ecosystem with its
players, its dominant platforms, its state-of-the-art practices and its
competitive geography.
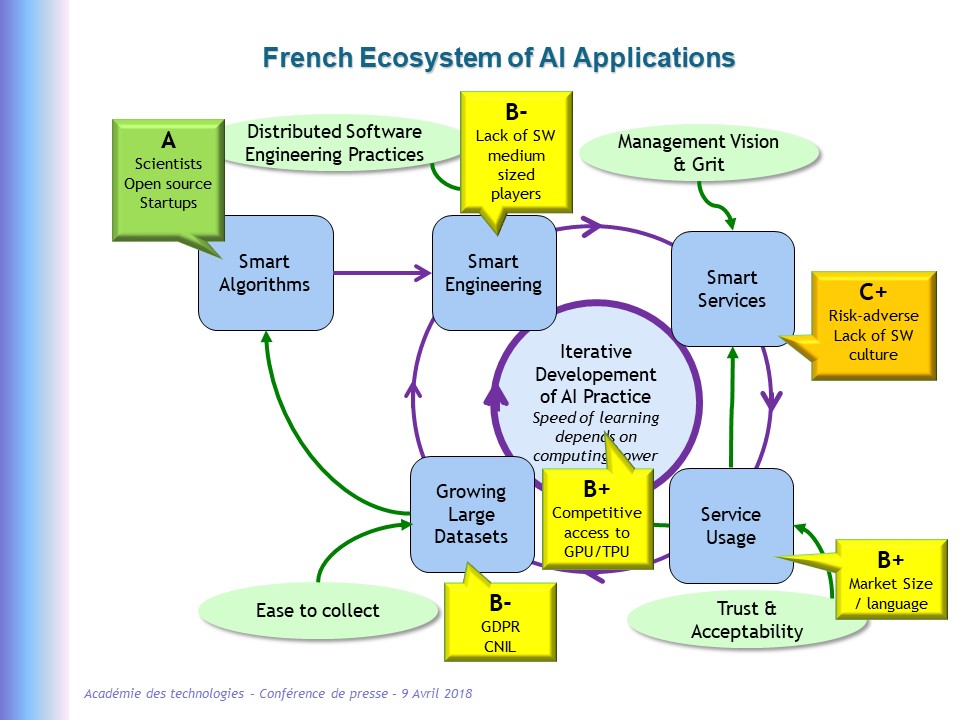
This figure, as well as a number of twin illustrations that may be found
on Twitter, illustrates the competitive
state of the French ecosystem:
- The “upstream” science & algorithms part of the ecosystem is doing pretty well. French scientists are sought over, their open source contributions are well spread and recognized, and the French AI startups are numerous.
- The “system engineering” step is less favorable to France since most major players are American (with the exception of China with its closed technology borders). Because of the massive advance of US in the digital world, practical expertise about large-scale distributed systems is more common in the US than in France. Trendsetting techniques in system engineering comes from the US, where they are better appreciated (cf. the success of Google’s “Site Reliability Engineering” book).
- The “service ecosystem” reflects the strength of demand, that is the desire from CEOs and executive committees to leverage exponential technologies to transform their organization. I am borrowing the wording from “Exponential Organizations” on purpose: there is a clear difference in technology-saviness and risk-appetite across the Ocean, as recalled by most technology suppliers (large and small) that we interviewed.
- The “service usage” ecosystem shows the disadvantage of Europe with its multiple languages and cultures compared to continent-states such as US or China. Trust is a major component of the willingness to try new digital services. We found that France is not really different from other European countries or even from the US but is lagging behind Asian countries such as South Korea or China.
- Data collection is harder in Europe that elsewhere, mostly because of stricter regulation and heavier bureaucracy. It is fashionable to see GDPR as a chance for Europe but we believe that GDPR should be softened with application rules that support experimentation.
- Last, although access to computing technology is ubiquitous, American companies tend to have a small edge as far as accessing large amounts of specialized resources is concerned.
One could argue with each of these assessments, finding them biased or
harsh, but what matters is the systemic loop structure. To see
where France will be compared to US or China five years from now, one must assess our ability
to run the cycles many, many times for each “AI + X” domain. Hence a small
disadvantage gets amplified many times (which is also why companies that started
earlier and that have accumulated data and practice tend to learn faster than
newcomers).
Stimulating the bottom-up growth of an emerging ecosystem is not easy,
it is much more difficult than promoting a top-down strategic plan. The report makes a few proposals, among which
I would like to emphasize the following four:
- Technical literature has been declining because of the Internet business model change, and this is especially keen for French technical press which is close to extinct. These communication channels used to play a key role for small innovative players to establish their credibility with regards to large corporate customers. Through hackathons, contests and challenges, technical evaluation, public spending and large-scale flagship projects, etc. public stakeholders must invest to help small but excellent technical players made their voices heard.
- Stimulating the “pull”, i.e., the demand for AI and machine learning solution, is itself a difficult task but it is not impossible. The communication efforts of public stakeholders should focus more on successful applications as opposed to the fascinating successes of technology providers.
- The NATF proposes to facilitate the setting up of Experimentation Centers associated to “IA + X” domains, through the creation of critical masses of data, talents, computing power and practices. An experimentation center would be a joint effort by different actors from the same business domain – in the spirit of an IRT – to build a platform where new algorithms could be tested against existing data sets and vice-versa.
- Last, following the recommendation from the CGEIET report, the NATF strongly supports the certification of data analytics processes, where the emphasis is on end-to-end certification from collection to continuous usage and improvement. Au
It should be also said that one will find in the NATF report a summary
of obviously relevant recommendations made in previous reports such as training
or better support for research and science. I strongly recommend the UK
report written by Wendy Hall and Jérôme Pesenti which addresses these topics
very thoroughly.
5. Conclusion
The
following is another “ecosystem schema” that I presented at the press
conference earlier this month to position the NATF report with respect to the
large crowd of reports and public figures’ opinions about Artificial
Intelligence. The structure is the same as the previous cycle, but one may see
that major ecosystems players have been spelled out. The short story is that
the upstream ecosystem deserves some attention obviously but the numerous
downstream ecosystems is where the battle should be fought, recognizing that France
is really late for regaining domination in the software platform world.

To summarize,
here is our contribution to the wonderful speech from the President Emmanuel
Macron about Artificial Intelligence:
- Don’t pick your battles too strongly in an emergent battlefield, promote and stimulate the large number of “AI+X” ecosystems. It is hard to guess where France will be better positioned 5 years from now.
- Follow Francois Julien recommendations on how to effectively promote an emergent ecosystem: It is about growth (agriculture) more than selection (hunting). What is required is more stimulation than actions.
- Focus on demand – how to encourage French companies to actively embrace the power of AI in their business activity – more than supply. Successful medium and large sizes AI companies will emerge in France if the local market exists.
In the same spirit, here is what the report says to
companies:
- Start collecting, sorting, enriching and thinking hard about your data,
- “Let your teams work” from a mindset and a working environment perspective,
- Think long-term, think “platform” and think about data flows.
Let me
conclude with a disclaimer: the content of the report is a group effort that
reflects as faithfully as possible the wisdom shared by the experts who were
interviewed during the past 2 years. This blog summary is tinted by the author’s
own experience with AI during the past 3 decades:
- 1984-1994 : Rules & Constraints on top of object-oriented language
- 1993-2003 : Program synthesis using randomization and reinforcement learning
- 2002-2012 : GTES: Evolutionary Game Theory
16 comments:
Looking for a SaaS App Development Company? Augurs Technologies is SaaS Application Development Company in India and develop custom applications for your growing business.
Good job in presenting the correct content with the clear explanation. The content looks real with valid information. Good Work
DevOps is currently a popular model currently organizations all over the world moving towards to it. Your post gave a clear idea about knowing the DevOps model and its importance.
Good to learn about DevOps at this time.
best devops training in Chennai | best devops certification course in Chennai | best devops training institute in Chennai
Hey, could I share your blog with my Twitter group? There are a lot of folks that would enjoy your content. Please let me know. Thank you.
Artificial Intelligence Training in Chennai
This article delves into a thought-provoking exploration of the Artificial Intelligence Applications Ecosystem and its reinforcing loops, offering valuable insights into its growth trajectory. The concept of reinforcing loops, as highlighted here, underscores the self-amplifying nature of AI's impact across diverse sectors. The comprehensive breakdown of various AI applications, from healthcare to finance, showcases the ecosystem's vast potential and its ability to create a virtuous cycle of innovation. The notion of AI as an enabler for solving complex problems and augmenting human capabilities is brilliantly elucidated. The article not only identifies these loops but also provides a strategic roadmap for nurturing them to achieve sustainable growth. By shedding light on the symbiotic relationships between technological advancements, data availability, and the evolving needs of industries, the piece establishes a clear path forward. Kudos to the author for unraveling the intricate dynamics of AI's ecosystem and offering an insightful guide to harnessing its reinforcing loops for a brighter technological future.
Erma Winter is a researcher, writer, and blogger covering topics related to technology, smart gadgets, the future of work, and personal productivity. She is the writer of Quokka Labs.
Visits their services:
Hire Android App Developers
Hire iOS App Developers
Best Mobile App Development Company
Top Android App Development Company
best iOS Application Development Company
It is important to assimilate the growth patterns loopy which develop the application and feedback culture of the artificial intelligence initiatives. AI apps can progressively transform into more productive and effective systems through regular feedback incorporation, algorithms modifications and data utilization. This is aimed at creating a loop where the next step is always an improvement from the previous one. For businesses, one of the ways of best life insurance landing page, is to generate more leads and engagement customer lastly increases more conversions and informative for further optimization.
I am thankful to you because your article is very helpful for me to carry on with my research in the same area. Your quoted examples are relevant to my research as well.
artificial intelligence in retail
thanks for sharing
Absolutely insightful! The clarity and actionability of your explanations really help in applying these tips effortlessly.
Ludo game development company
Thanks for sharing the quality information with us. Really liked reading the post.
ai go to market
very good post thanks for sharing it.
AI As A Service
Machine Learning Development Company
Ai Development Company
Generative Ai Development Company
AI Chatbot Development Company
This is a sharp and insightful analysis of France’s AI ecosystem. The emphasis on downstream development and practical deployment really hits home. Supporting experimentation, showcasing successful use cases, and amplifying technical voices are crucial steps forward. For more on tech trends and innovation strategies, visit Supportsoft
Nice article and information sir...
Artificial Hedge
This is a very insightful article on the AI applications ecosystem and how reinforcing loops can drive growth. Understanding these loops is crucial for businesses looking to innovate efficiently. For companies exploring practical implementations, leveraging AI App Development Services can help transform these concepts into real-world solutions.
Post a Comment